
日本語も読み上げられるようにするべき
以前、『スピーチ VS. デイジー』というエントリで「おそらく今後は世界的にEPUBの読み上げが当たり前になり、読み間違い問題を克服できない日本語だけが取り残される」という趣旨の予想を書きました。 でもそれって不幸ですよね。とりわけ一番の当事者である日本の視覚障害者とその支援者は、デイジー関連の機器、オーサリングツール類のアップグレードやサポートが止まって世界から取り残された悲哀を味わうことになり兼ねません。 ならば日本語もできるだけ早く正確に読み上げられるようにするべきです。方法は二つ。
- 強力な辞書を持たせる
- テキストの要所にことごとく読みの情報を持たせる
ただし1の方法はダメですね。「苺愛=べりーあ」「黄熊=ぷう」といった今どきのキラキラネームには対処できるものの、ロシア文学者の江川卓(えがわたく)氏と元巨人軍投手の江川卓(えがわすぐる)氏の読み分けは不可能です。 他にも「今日は=こんにちは/きょうは」や「方々=かたがた/ほうぼう」の使い分けには辞書だけでなく高精度の構文解析アルゴリズムとCPUパワーが必要です。 よって2の方法しかありません。
phonic(仮)
大仰にはなるものの、テキストの全文にわたって読みを付けると腹を括れば考え方は単純になります。 具体的にはHTMLの<ruby>と同様に読み上げのためのマークアップを導入するのが良いでしょう。ここでは仮に<phonic>とします。「phonic」は「音(声)に関係のある」という意味の英語ですね。もっと相応しい名称や表記方法があれば、そちらで置き換えて読み進めていただけるとあり難いです。非対応のブラウザ等との互換性に配慮するなら<span>を使った表記になるかな。 以下はガリバー旅行記の一節。
私の足の上を、何か生物が、ゴソ/\這っているようです。
昔の表記なので繰り返しを記号で表現しています。これに読みを付けるとこうなります。
私の足の上を、何か生物が、 <phonic>ゴソ/\<pt>ごそごそ</pt></phonic>這っているようです。
「<phonic>ゴソ/\</phonic>」の文字列は表示し、「<pt>ごそごそ</pt>」は非表示とします。それを<phonic>に対応したWebブラウザなりプレイヤーアプリが以下のように読み上げるわけです。
わたしのあしのうえを、なにかいきものが、 ごそごそはっているようです。
これには当然ながらプレイヤー側の対応も必須になります。
オーサリングツールも必要だ
作成においても手作業でタグを書き入れるのは現実的ではないので、それ用のオーサリングツールが必要です。 読みのタグ設定は串刺し検索置換を駆使するタイプの対応テキストエディタがあればよいでしょう。こんな感じかな。
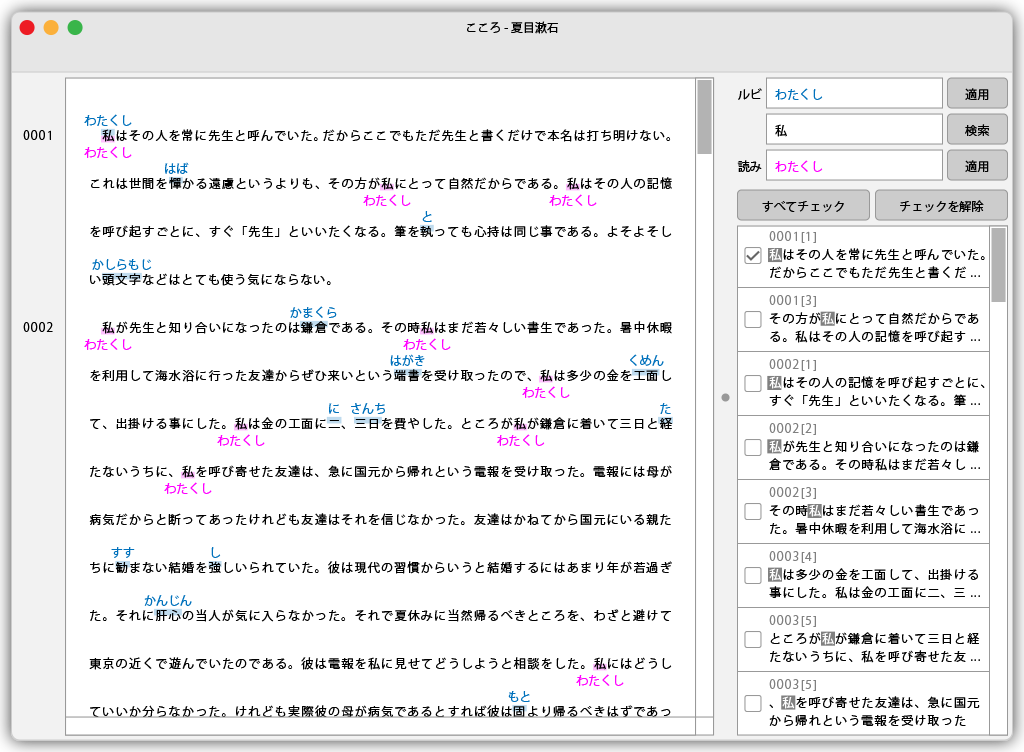
想定する使い方:
ウインドウ右上の検索フィールドに目当ての文字列を入力して検索。 その下にヒットした文字列が一覧表示されるので、読みを付けたい箇所にチェックを付ける。 読みのフィールドに文字列を入力して「適用」ボタンをクリックすると、本文の該当箇所に<phonic>の読みが付与される。
EPUBのテキストをインポートして読みを付けてエクスポートできると尚よし。 もちろん長編小説なんかだと読みの付与は大変な作業になるけど、それでも朗読してデイジーにするよりは圧倒的に楽。しかもデイジーとは違ってコンテンツを視覚障害者以外にも提供できます。
<ruby>じゃダメなの?
「わざわざ新たな<phonic>を提唱せずとも既にEPUBなどの標準規格に盛り込まれている<ruby>を使えばいいのでは?」というご意見もありましょう。ごもっともです。それならプレイヤー側が対応しさえすれば、すぐにでも読み間違わない読み上げが実現します。 ただし、懸案が二つほど。
- 画面がルビだらけになると読みづらい
- ルビは日本語独自の概念にすぎない
1. は、例えば小説の場合、人名や地名が初めて登場する箇所にだけルビを振ったものが多く見られます。もちろん2回目以降に登場する語はcssで消してしまえば(文字色を背景と同じ色に設定すれば)済むかもしれません。でも、ややこしいですよね。
江川<ruby class=”dispable”>卓<rt>たく</rt></ruby>氏はロシア文学者である。
なんて表記ルールで、しかも別途CSSにも.dispableに対する非表示処理が必要なんてことでは。いや、その方法では上記の例の「卓」まで消えかねないか。 だったら、
江川<phonic>卓<pt>たく</pt></phonic>氏はロシア文学者である。
と指定するだけの方が簡潔です。この点は先々国際標準規格に採用してもらうにあたってはとても重要になります。
実は日本語以外でも有用
日本語ほどではないにしろ外国語でも合成音声エンジンによる読み間違いはあります。 例えばローマ数字。
Super Bowl XLIX
普通にコンピュータに読ませれば、TTSエンジン(読み上げの機構)によっては「スーパーボウル エックスエルアイエッックス」と読みかねないので、このように書きます。
Super Bowl <phonic>XLIX<pt>49th</pt></phonic>
あるいはコロンビアの人気サッカー選手のJames Rodriguezという名前を英語のエンジンで読み上げさせれば「ジェームズ・ロドリゲス」。でも近年では母国での発音を重視するのでJamesは「ハメス」と読み上げさせたいところ。ただし英語圏でジェームズを名乗っているロドリゲスさんはジェームズと読ませなければなりません。 よって必要に応じて以下のような表記にすれば解決します。読みの指定には発音記号もありってことで。
<phonic>James<pt>ha me θ</pt></phonic>Rodriguez
もしくはこうかな。
<phonic lang=”es”>James</phonic>Rodriguez
英語の読み上げエンジンであっても、そこだけはスペイン語として読むわけですね。 そんなわけなので「読み」の概念は案外、国際標準規格にも採用してもらいやすいのではないかと。
悔やまれるのは
悔やまれるのはEPUBに日本語独自の概念を盛り込ませた際(2010年ごろだったかな)に、読み上げ対策への考慮が欠けていたこと。
まずは第一歩を踏み出すべき
まあ過ぎたことを悔いてもしかたないので前を向きましょう。
全文にわたって読みを付ける方法は「ひらがな・カタカナに直して読み上げさせる」に近いのだから、イントネーションはあてずっぽうになりがちです。
でも、それはカーナビの音声やSiriの返答なんかもそう。人々は多少ぎこちない話し方にも慣れているし、それよりも「読み間違わない」の実現にこぎ着けることがずっとずっと重要だろうと。
それに、<phonic>の書式を拡張すれば、任意の箇所に意図的に間を空けたり、イントネーションの指定や発音記号による読みの設定なんかにも対応可能なはずです。
今の視覚障害者支援の拙さ
私は日本の視覚障害者支援の実情を少しだけ知っているのですが、とても残念に思うことがあります。それは「皆、障害者のことしか考えていない」です。変な言い方に聞こえるかもしれないけど、その真面目さがかえって視覚障害者支援の進歩のスピードを遅らせているように思えてならないのですよね。
現状、デイジー録音図書の制作などでは、志の高いボランティアの方々が「視覚障害者の役に立ちたい」の一心でもって各々に出来ることに日々尽力しています。そのことには敬服するのですが、成果を上げるためには多くの時間がかかり、ともするとシニアのスタッフが次々とリタイヤしてしいつしか頓挫、なんてことにもなり兼ねません。
また文部科学省や厚生労働省も「既にボランティアベースで成り立っているのだから、それでいいじゃないか」とばかりに見て見ぬふりで予算をつけようとしません。政治家もそう。視覚障害者は圧倒的マイノリティなので票田にもならないですしね。
とはいえボランティアが取り組みをやめれば政治・行政が動いてくれるわけでもなく、ただただ新作デイジー制作の空白期間が生まれてしまいます。政治や行政は頼りになってはくれません。
つまりは既存の枠組みの延長で取り組む限り現状維持が精いっぱいといったところです。
よってこの際、晴眼者、健常者を巻き込み、ボランティアベースではなくビジネスベースに乗せられる方向に持って行くべきだろうと。
様々な応用可能
まずは電子書籍。デイジーではなくEPUBが読み上げ可能になれば、晴眼者に売れます。老眼が進んだ人やレーシック手術の後遺症で活字が読みづらい人、運転中や満員の通勤電車内で聴きたい人など、紙の本は買わなかった層にアピールできれば売り上げ増も見込めます。
他にもニュース系のWebサイトが<phonic>で読みを指定すれば、「ニュースサイト読み上げアプリ」が作れます。
人気の有料Podcastである「聴く日経」は毎朝早朝からアナウンサーが原稿を読み上げて制作、配信されていますが、それと同じことを人間が読み上げることなくテキストベースの作業で可能になります。Yahoo!ニュースのSNSボタンの横あたりに「読み上げ」ボタンが付いてて、タップすると読み上げるようになると便利ですよね。
あるいは、企業や自治体の広報作成担当者が、作成した原稿を読み上げさせて校正、確認するといった用途に使うようになれば、<phonic>対応のオーサリングツールはかなりの数が売れることでしょう。目読による校正は先入観で問題箇所をスルーしがちになるものの、耳で聴けば違和感でもって気づきやすいので。
目ぼしいOSの読み上げエンジンが対応すればWordPressのプラグインなんかも登場するかも知れません。書いたエントリの確認用途ですね。
個人的にはAdobe InDesignでドキュメントを作る際に読みも付けられ、PDFも正確に読み上げられるようになれば嬉しいです。
来るべき理想社会
そうして視覚障害者に限らない利用分野での読み上げ可能テキストが普及、浸透すれば自ずと視覚障害者への恩恵も多分にもたらされます。それこそボランティアが今のまま10年頑張っても辿り着けない境地へ僅か1年かそこらで到達できるやもしれません。
「官公庁や大企業などのWebページには読みが付いているのが当たりまえ」という風潮は無理なく作れるでしょうし、「新たに発売されるテキスト主体の出版物には読みを付けなければならない」という法制度すら可能になるかも知れません。
何か話題の新刊本が出る際に、現状のようにボランティアが印刷の本を朗読して何週間も費やしてデイジー録音図書を作らずとも、最初から読み間違わないEPUBが発売日に流通するようになれば、どれだけ良いか。
私のFacebookページ:IT.FROGFISH.JP